sc.exe create "<serviceKey>" start= auto binPath= "<path to jenkins-slave.exe>" DisplayName= "<service display name>"Architecting for Scale
Table of Contents
Introduction
As an organization matures from a continuous delivery standpoint, its Jenkins requirements will similarly grow. This growth is often reflected in the Jenkins architecture, whether that be "vertical" or "horizontal" growth.
Vertical growth is when the load on a Jenkins controller load is increased by having more configured jobs or orchestrating more frequent builds. This may also mean that more teams are depending on that one controller.
Horizontal growth is the creation of additional Jenkins controllers to accommodate new teams or projects, rather than adding new teams or projects to an existing controller.
There are potential pitfalls associated with each approach to scaling Jenkins, but with careful planning, many of them can be avoided or managed. Here are some things to consider when choosing a strategy for scaling your organization’s Jenkins controllers:
-
Do you have the resources to run a distributed build system? If possible, it is recommended set up dedicated build nodes that run separately from the Jenkins controller. This frees up resources for the controller to improve its scheduling performance and prevents builds from being able to modify any potentially sensitive data in the $JENKINS_HOME. This also allows for a single controller to scale far more vertically than if that controller were both the job builder and scheduler.
-
Do you have the resources to maintain multiple controllers? Jenkins controllers require regular plugin updates, semi-monthly core upgrades, and regular backups of configurations and build histories. Security settings and roles will have to be manually configured for each controller. Downed controllers will require manual restart of the Jenkins controller and any jobs that were killed by the outage.
-
How mission critical are each team’s projects? Consider segregating the most vital projects to separate controllers to minimize the impact of a single downed controller. Also consider converting any mission-critical project pipelines to Pipeline jobs, which continue executing even when the agent connection to the controller is lost.
-
How important is a fast start-up time for your Jenkins controller? The more jobs a controller has configured, the longer it takes to load Jenkins after an upgrade or a crash. The use of folders and views to organize jobs can limit the number of that need to be rendered on start up.
Distributed Builds Architecture
A Jenkins controller can operate by itself both managing the build environment and executing the builds with its own executors and resources. If you stick with this "standalone" configuration you will most likely run out of resources when the number or the load of your projects increase.
To come back up and running with your Jenkins infrastructure you will need to enhance the controller (increasing memory, number of CPUs, etc). The time it takes to maintain and upgrade the machine, the controller together with all the build environment will be down, the jobs will be stopped and the whole Jenkins infrastructure will be unusable.
Scaling Jenkins in such a scenario would be extremely painful and would introduce many "idle" periods where all the resources assigned to your build environment are useless.
Moreover, executing jobs on the controller introduces a "security" issue: the "jenkins" user that Jenkins uses to run the jobs would have full permissions on all Jenkins resources on the controller. This means that, with a simple script, a malicious user can have direct access to private information whose integrity and privacy could not be, thus, guaranteed. See Distributed Builds in the Securing Jenkins chapter for more information.
For all these reasons Jenkins supports agents, where the workload of building projects are delegated to multiple agents.
An agent is a machine set up to offload projects from the controller. The method with which builds are scheduled depends on the configuration given to each project. For example, some projects may be configured to "restrict where this project is run" which ties the project to a specific agent or set of labeled agents. Other projects which omit this configuration will select an agent from the available pool in Jenkins. Learn more about Agents in Managing Nodes
In a distributed builds environment, the Jenkins controller will use its resources to only handle HTTP requests and manage the build environment. Actual execution of builds will be delegated to the agents. With this configuration it is possible to horizontally scale an architecture, which allows a single Jenkins installation to host a large number of projects and build environments.
Agent communications
In order for a machine to be recognized as an agent, it needs to run a specific agent program to establish bi-directional communication with the controller.
There are different ways to establish a connection between controller and agent:
-
The SSH connector: Configuring an agent to use the SSH connector is the preferred and the most stable way to establish controller-agent communication. Jenkins has a built-in SSH client implementation. This means that the Jenkins controller can easily communicate with any machine with an SSH server installed. The only requirement is that the public key of the controller is part of the set of the authorized keys on the agent. Once the host and SSH key is defined for a new agent, Jenkins will establish a connection to the machine and bootstrap the agent process.
-
The inbound connector: In this case the communication is established starting the agent through a connection initiated by an agent program. With this connector the agent is launched in the machine in 2 different ways:
-
Manually: by navigating to the Jenkins controller URL in a browser on the agent. Once the Java Web Start icon is clicked, the agent will be launched on the machine. The downside of this approach is that the agents cannot be centrally managed by the Jenkins controller and each/stop/start/update of the agent needs to be executed manually on the agent’s machine in versions of Jenkins older than 1.611. This approach is convenient when the controller cannot instantiate the connection with the client, for example: with agents running inside a firewalled network connecting to a controller located outside the firewall.
-
As a service: First you’ll need to manually launch the agent using the above method. After manually launching it, jenkins-slave.exe and jenkins-slave.xml will be created in the agent’s work directory. Now go to the command line to execute the following command:
-
<serviceKey> is the name of the registry key to define this agent service and <service display name> is the label that will identify the service in the Service Manager interface.
To ensure that restarts are automated, you will need to download a recent agent jar and copy it to a permanent location on the machine. The_.jar_ file can be found at:
http://<your-jenkins-host>/jnlpJars/agent.jarIf running a version of Jenkins newer than 1.559, the .jar will be kept up to date each time it connects to the controller.
-
The Inbound-HTTP connector: This approach is quite similar to the Inbound-TCP Java Web Start approach, with the difference in this case being that the agent is executed as headless and the connection can be tunneled via HTTP(s). The exact command can be found on your Inbound agent’s configuration page:
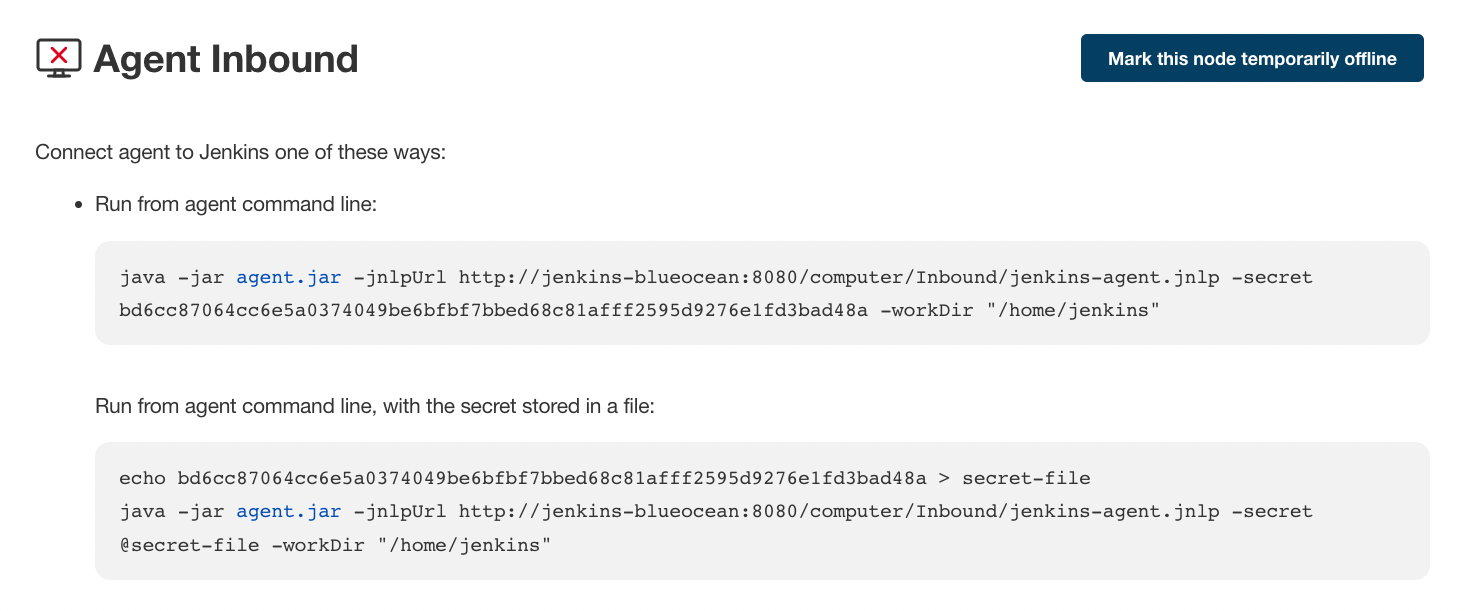
Figure 1. Inbound agent launch command
This approach is convenient for an execution as a daemon on Unix.
-
Custom-script: It is also possible to create a custom script to initialize the communication between controller and agent if the other solutions do not provide enough flexibility for a specific use-case. The only requirement is that the script runs the java program as a java -jar agent.jar on the agent.
Windows agent set-up can follow the standard SSH and inbound agent approaches. Windows agents have the following options:
-
SSH-connector approach with Putty
-
SSH-connector approach with Cygwin and OpenSSH: This is the easiest to setup and recommended approach.
-
SSH-connector approach with Microsoft OpenSSH: The Microsoft OpenSSH server works well for Microsoft operating systems that support the server. Refer to installation instructions in the ssh build agents configuration guide.
-
Inbound agent approach: With this approach it is possible to manually register the agent as Windows service, but it will not be possible to centrally manage it from the controller. Each stop/start/update of the agent needs to be executed manually on the agent machine, unless running Jenkins 1.611 or newer.
Creating fungible agents
Configuring tools location on agents
The Jenkins Global configuration page lets you specify the tools needed during the builds (i.e. Ant, Maven, Java, etc).
When defining a tool, it is possible to create a pointer to an existing installation by giving the directory where the program is expected to be on the agent. Another option is to let Jenkins take care of the installation of a specific version in the given location. It is also possible to specify more than one installation for the same tool since different jobs may need different versions of the same tool.
The pre-compiled "Default" option calls whatever is already installed on the agent and exists in the machine PATH, but this returns a failure if the tool is not installed and its location was not added to the PATH system variable.
One best practice to avoid this failure is to configure a job with the assumption that the target agent does not have the necessary tools installed, and to include the tools' installation as part of the build process.
Define a policy to share agent machines
As mentioned previously, agents should be interchangeable and standardized in order to make them sharable and to optimize resource usage. Agents should not be customized for a particular set of jobs, nor for a particular team.
Lately Jenkins has become more and more popular not only in CI but also in CD, which means that it must orchestrate jobs and pipelines which involve different teams and technical profiles: developers, QA people and Dev-Ops people.
In such a scenario, it might make sense to create customized and dedicated agents: different tools are usually required by different teams (i.e. Puppet/Chef for the Ops team) and teams' credentials are usually stored on the agent in order to ensure their protection and privacy.
In order to ensure the execution of a job on a single/group of agents only (i.e. iOS builds on OSX agents only), it is possible to tie the job to the agent by specifying the agent’s label in the job configuration page. Note that the restriction has to be replicated in every single job to be tied and that the agent won’t be protected from being used by other teams.
Setting up cloud agents
Cloud build resources can be a solution for a case when it is necessary to maintain a reasonably small cluster of agents on-premises while still providing new build resources when needed.
In particular it is possible to offload the execution of the jobs to agents in the cloud thanks to ad-hoc plugins which will handle the creation of the cloud resources together with their destruction when they are not needed anymore:
-
The EC2 Plugin lets Jenkins use AWS EC2 instances as cloud build resources when it runs out of on-premises agents. The EC2 agents will be dynamically created inside an AWS network and de-provisioned when they are not needed.
-
The Azure VM Agents Plugin dynamically spins up Jenkins agents as Azure VMs per user provided configuration via templates, including support for virtual network integration and subnet placement. Idle agents can be configured for automatic shutdown to reduce costs.
-
The JCloud plugin creates the possibility of executing the jobs on any cloud provider supported by JCloud libraries
Right-sizing Jenkins controllers
Comprehensive hardware recommendations:
-
Hardware: see the Hardware Recommendations page
Controller division strategies
Designing the best Jenkins architecture for your organization is dependent on how you stratify the development of your projects and can be constrained by limitations of the existing Jenkins plugins.
The 3 most common forms of stratifying development by controllers is:
-
By environment (QA, DEV, etc) - With this strategy, Jenkins controllers are populated by jobs based on what environment they are deploying to.
-
Pros
-
Can tailor plugins on controllers to be specific to that environment’s needs
-
Can easily restrict access to an environment to only users who will be using that environment
-
-
Cons
-
Reduces ability to create pipelines
-
No way to visualize the complete flow across controllers
-
Outage of a controller will block flow of all products
-
-
-
By org chart - This strategy is when controllers are assigned to divisions within an organization.
-
Pros
-
Can tailor plugins on controllers to be specific to that team’s needs
-
Can easily restrict access to a division’s projects to only users who are within that division
-
-
Cons
-
Reduces ability to create cross-division pipelines
-
No way to visualize the complete flow across controllers
-
Outage of a controller will block flow of all products
-
-
-
Group controllers by product lines - When a group of products, with on only critical product in each group, gets its own Jenkins controllers.
-
Pros
-
Entire flows can be visualized because all steps are on one controller
-
Reduces the impact of one controller’s downtime on only affects a small subset of products
-
-
Cons
-
A strategy for restricting permissions must be devised to keep all users from having access to all items on a controller.
-
-
When evaluating these strategies, it is important to weigh them against the vertical and horizontal scaling pitfalls discussed in the introduction.
Another note is that a smaller number of jobs translates to faster recovery from failures and more importantly a higher mean time between failures.
Calculating how many jobs, controllers, and executors are needed
Having the best possible estimate of necessary configurations for a Jenkins installation allows an organization to get started on the right foot with Jenkins and reduces the number of configuration iterations needed to achieve an optimal installation. The challenge for Jenkins architects is that true limit of vertical scaling on a Jenkins controller is constrained by whatever hardware is in place for the controller, as well as harder to quantify pieces like the types of builds and tests that will be run on the build nodes.
There is a way to estimate roughly how many controllers, jobs and executors will be needed based on build needs and number of developers served. These equations assume that the Jenkins controller will have 5 cores with one core per 100 jobs (500 total jobs/controller) and that teams will be divided into groups of 40.
If you have information on the actual number of available cores on your planned controller, you can make adjustments to the "number of controllers" equations accordingly.
The equation for estimating the number of controllers and executors needed when the number of configured jobs is known is as follows:
controllers = number of jobs/500
executors = number of jobs * 0.03The equation for estimating the maximum number of jobs, controllers, and executors needed for an organization based on the number of developers is as follows:
number of jobs = number of developers * 3.333
number of controllers = number of jobs/500
number of executors = number of jobs * 0.03These numbers will provide a good starting point for a Jenkins installation, but adjustments to actual installation size may be needed based on the types of builds and tests that an installation runs.
Scalable storage for controllers
It is also recommended to choose a controller with consideration for future growth in the number of plugins or jobs stored in your controller’s $JENKINS_HOME. Storage is cheap and Jenkins does not require fast disk access to run well, so it is more advantageous to invest in a larger machine for your controller over a faster one.
Different operating systems for the Jenkins controller will also allow for different approaches to expandable storage:
-
Spanned Volumes on Windows - On NTFS devices like Windows, you can create a spanned volume that allows you to add new volumes to an existing one, but have them behave as a single volume. To do this, you will have to ensure that Jenkins is installed on a separate partition so that it can be converted to a spanned volume later.
-
Logical Volume Manager for Linux - LVM manages disk drives and allows logical volumes to be resized on the fly. Many distributions of Linux use LVM when they are installed, but Jenkins should have its own LVM setup.
-
ZFS for Solaris - ZFS is even more flexible than LVM and spanned volumes and just requires that the $JENKINS_HOME be on its own filesystem. This makes it easier to create snapshots, backups, etc.
-
For systems with an existing Jenkins installation, there are at least two options:
-
The System Property jenkins.model.Jenkins.buildsDir
-
Symbolic Links (symlinks) may be used instead to store job folders on separate volumes with symlinks to those directories.
-
-
Additionally, to easily prevent a $JENKINS_HOME folder from becoming bloated, make it mandatory for jobs to discard build records after a specific time period has passed and/or after a specific number of builds have been run. This policy can be set on a job’s configuration page.
Setting up a backup policy
It is a best practice to take regular backups of your $JENKINS_HOME. A backup ensures that your Jenkins controller can be restored despite a misconfiguration, accidental job deletion, or data corruption. See the Backup policies for more details.
Finding your $JENKINS_HOME
Windows
If you install Jenkins with the Windows installer, Jenkins is installed as a service and the default $JENKINS_HOME will be "C:\Program Files (x86)\jenkins". You can edit the location of your $JENKINS_HOME by opening the jenkins.xml file and editing the $JENKINS_HOME variable, or going to the "Manage Jenkins" screen, clicking on the "Install as Windows Service" option in the menu, and then editing the "Installation Directory" field to point to another existing directory.
Mac OSX
If you install Jenkins with the OS X installer, you can find and edit the location of your $JENKINS_HOME by editing the "Macintosh HD/Library/LaunchDaemons" file’s $JENKINS_HOME property.
By default, the $JENKINS_HOME will be set to "Macintosh HD/Users/Shared/Jenkins".
Linux
By default, $JENKINS_HOME is set to /var/lib/jenkins
and $JENKINS_WAR is set to /usr/share/java/jenkins.war.
You can edit the location of $JENKINS_HOME
by running systemctl edit jenkins and adding the following:
[Service]
Environment="HOME=/var/lib/jenkins"
Environment="JENKINS_HOME=/var/lib/jenkins"
WorkingDirectory=/var/lib/jenkinsYou can edit the location of $JENKINS_WAR
by running systemctl edit jenkins and adding the following:
[Service]
Environment="JENKINS_WAR=/usr/share/java/jenkins.war"FreeBSD
If installing Jenkins using a port, the $JENKINS_HOME will be located in whichever directory you run the "make" command in. It is recommended to create a "/usr/ports/devel/jenkins" folder and compile Jenkins in that directory.
You will be able to edit the $JENKINS_HOME by editing the "/usr/local/etc/jenkins".
OpenBSD
If installing Jenkins using a package,the $JENKINS_HOME is set by default to "/var/jenkins".
If installing Jenkins using a port, the $JENKINS_HOME will be located in whichever directory you run the "make" command in. It is recommended to create a "/usr/ports/devel/jenkins" folder and compile Jenkins in that directory.
You will be able to edit the $JENKINS_HOME by editing the "/usr/local/etc/jenkins" file.
Solaris/OpenIndiana
The Jenkins project voted on September 17, 2014 to discontinue Solaris packages.
Anatomy of a $JENKINS_HOME
The folder structure for a $JENKINS_HOME directory is as follows:
JENKINS_HOME
+- config.xml (Jenkins root configuration file)
+- *.xml (other site-wide configuration files)
+- identity.key (RSA key pair that identifies an instance)
+- secret.key (deprecated key used for some plugins' secure operations)
+- secret.key.not-so-secret (used for validating _$JENKINS_HOME_ creation date)
+- userContent (files served under your https://server/userContent/)
+- secrets (root directory for the secret+key for credential decryption)
+- hudson.util.Secret (used for encrypting some Jenkins data)
+- master.key (used for encrypting the hudson.util.Secret key)
+- InstanceIdentity.KEY (used to identity this instance)
+- fingerprints (stores fingerprint records, if any)
+- plugins (root directory for all Jenkins plugins)
+- [PLUGINNAME] (sub directory for each plugin)
+- META-INF (subdirectory for plugin manifest + pom.xml)
+- WEB-INF (subdirectory for plugin jar(s) and licenses.xml)
+- [PLUGINNAME].jpi (.jpi or .hpi file for the plugin)
+- jobs (root directory for all Jenkins jobs)
+- [JOBNAME] (sub directory for each job)
+- config.xml (job configuration file)
+- workspace (working directory for the version control system)
+- latest (symbolic link to the last successful build)
+- builds (stores past build records)
+- [BUILD_ID] (subdirectory for each build)
+- build.xml (build result summary)
+- log (log file)
+- changelog.xml (change log)
+- [FOLDERNAME] (sub directory for each folder)
+- config.xml (folder configuration file)
+- jobs (sub directory for all nested jobs)Segregating pure configuration from less durable data
| No data migration is handled by Jenkins when using those settings. So you either want to use them from the beginning, or make sure you take into consideration which data you would like to be moved to the right place before using the following switches. |
It is possible to separate customize some of the layout to better separate pure job configurations from less durable data, like build data or logs. [1]
Configure a different jobs build data layout
Historically, the configuration of a given job is located under $JENKINS_HOME/jobs/[JOB_NAME]/config.xml and its builds are under $JENKINS_HOME/jobs/[JOB_NAME]/builds.
This typically makes it more impractical to set up a different backup policy, or set up a quicker disk for making builds potentially faster.
For instance, if you would like to move builds under a different root, you can use the following value: $JENKINS_VAR/${ITEM_FULL_NAME}/builds.
Note that starting with Jenkins 2.119, the User Interface for this was replaced by the jenkins.model.Jenkins.buildsDir system property. See the dedicated Features Controlled with System Properties wiki page for more details.
Choosing a backup strategy
All of your Jenkins-specific configurations that need to be backed up will live in the $JENKINS_HOME, but it is a best practice to back up only a subset of those files and folders.
Below are a few guidelines to consider when planning your backup strategy.
Exclusions
When it comes to creating a backup, it is recommended to exclude archiving the following folders to reduce the size of your backup:
/war (the exploded Jenkins war directory) /cache (downloaded tools) /tools (extracted tools)
These folders will automatically be recreated the next time a build runs or Jenkins is launched.
Jobs and Folders
Your job or folder configurations, build histories, archived artifacts, and workspace will exist entirely within the jobs folder.
The jobs directory, whether nested within a folder or at the root level is as follows:
+- jobs (root directory for all Jenkins jobs)
+- [JOBNAME] (sub directory for each job)
+- config.xml (job configuration file)
+- workspace (working directory for the version control system)
+- latest (symbolic link to the last successful build)
+- builds (stores past build records)
+- [BUILD_ID] (subdirectory for each build)
+- build.xml (build result summary)
+- log (log file)
+- changelog.xml (change log)If you only need to backup your job configurations, you can opt to only backup the config.xml for each job. Generally build records and workspaces do not need to be backed up, as workspaces will be re-created when a job is run and build records are only as important as your organizations deems them.
System configurations
Your instance’s system configurations exist in the root level of the $JENKINS_HOME folder:
+- config.xml (Jenkins root configuration file) +- *.xml (other site-wide configuration files)
The config.xml is the root configuration file for your Jenkins. It includes configurations for the paths of installed tools, workspace directory, and agent port.
Any .xml other than that config.xml in the root Jenkins folder is a global configuration file for an installed tool or plugin (i.e. Maven, Git, Ant, etc). This includes the credentials.xml if the Credentials plugin is installed.
If you only want to backup your core Jenkins configuration, you only need to back up the config.xml.
Plugins
Your instance’s plugin files (.hpi and .jpi) and any of their dependent resources (help files, pom.xml files, etc) will exist in the plugins folder in $JENKINS_HOME.
+- plugins (root directory for all Jenkins plugins)
+- [PLUGINNAME] (sub directory for each plugin)
+- META-INF (subdirectory for plugin manifest + pom.xml)
+- WEB-INF (subdirectory for plugin jar(s) and licenses.xml)
+- [PLUGINNAME].jpi (.jpi or .hpi file for the plugin)
It is recommended to back up the entirety of the plugins folder (.hpi/.jpis + folders).
Other data
Other data that you are recommended to back up include the contents of your secrets folder, your identity.key, your secret.key, and your secret.key.not-so-secret file.
+- identity.key (RSA key pair that identifies an instance)
+- secret.key (used for various secure Jenkins operations)
+- secret.key.not-so-secret (used for validating _$JENKINS_HOME_ creation date)
+- userContent (files served in https://server/userContent/)
+- secrets (directory for the secret+key decryption)
+- hudson.util.Secret (used for encrypting some Jenkins data)
+- master.key (used for encrypting the hudson.util.Secret key)
+- InstanceIdentity.KEY (used to identity this instance)
The identity.key is an RSA key pair that identifies and authenticates the current Jenkins controller.
The secret.key is used to encrypt plugin and other Jenkins data, and to establish a secure connection between a controller and agent.
The secret.key.not-so-secret file is used to validate when the $JENKINS_HOME was created. It is also meant to be a flag that the secret.key file is a deprecated way of encrypting information.
The files in the secrets folder are used by Jenkins to encrypt and decrypt your instance’s stored credentials, if any exist. Loss of these files will prevent recovery of any stored credentials. hudson.util.Secret is used for encrypting some Jenkins data like the credentials.xml, while the master.key is used for encrypting the hudson.util.Secret key. Finally, the InstanceIdentity.KEY is used to identity this instance and for producing digital signatures.
Define a Jenkins controller to rollback to
In the case of a total machine failure, it is important to ensure that there is a plan in place to get Jenkins both back online and in its last good state.
If a high availability set up has not been enabled and no back up of that controller’s filesystem has been taken, then an corruption of a machine running Jenkins means that all historical build data and artifacts, job and system configurations, etc. will be lost and the lost configurations will need to be recreated on a new instance.
-
Backup policy - In addition to creating backups using the previous section’s backup guide, it is important to establish a policy for selecting which backup should be used when restoring a downed controller.
-
Restoring from a backup - A plan must be put in place on whether the backup should be restored manually or with scripts when the primary goes down.
Resilient Jenkins Architecture
Administrators are constantly adding more and more teams to the software factory, making administrators in the business of making their instances resilient to failures and scaling them in order to onboard more teams.
Adding build nodes to a Jenkins controller while beefing up the machine that runs the Jenkins controller is the typical way to scale Jenkins. Said differently, administrators scale their Jenkins controller vertically. However, there is a limit to how much an instance can be scaled. These limitations are covered in the introduction to this chapter.
Ideally, controllers will be set up to automatically recover from failures without human intervention. There are proxy servers monitoring active controllers and re-routing requests to backup controllers if the active controller goes down. There are additional factors that should be reviewed on the path to continuous delivery. These factors include componetizing the application under development, automating the entire pipeline (within reasonable limits) and freeing up contentious resources.
Step 1: Make each controller highly available
Each Jenkins controller needs to be set up such that it is part of a Jenkins cluster.
A proxy (typically HAProxy or F5) then fronts the primary controller. The proxy’s job is to continuously monitor the primary controller and route requests to the backup if the primary goes down. To make the infrastructure more resilient, you can have multiple backup controllers configured.
Step 2: Enable security
Set up an authentication realm that Jenkins will use for its user database.
| If you are trying to set up a proof-of-concept, it is recommended to use the Mock Security Realm plugin for authentication. |
Step 3: Add build nodes (agents) to controller
Add build servers to your controller to ensure you are conducting actual build execution off of the controller, which is meant to be an orchestration hub, and onto a "dumb" machine with sufficient memory and I/O for a given job or test.
Step 4: Setup a test instance
A test instance is typically used to test new plugin updates. When a plugin is ready to be used, it should be installed into the main production update center.
1. These switches are used to configure out of the box Jenkins Essentials instances.
Please submit your feedback about this page through this quick form.
Alternatively, if you don't wish to complete the quick form, you can simply indicate if you found this page helpful?
See existing feedback here.